.png)
.png)

In this article:
- What is health data standardisation?
- Why is health data standardisation important?
- What are the benefits of standardising health data?
- Enabling health data standardisation - technical challenges and solutions
- Key players driving health data standardisation
- Health data standardisation in action: enabling data linkage
- Health data standardisation: one part of the end-to-end data analysis pipeline
What is health data standardisation?
Let’s start with some background and context: healthcare is one of the most data-rich industries with exponential growth in data. This health data is needed to solve crucial scientific questions (eg, causes of rare diseases or the efficacy of a new drug). The data can come from a wide variety of sources. As a result, the data can exist in many different formats and be stored in many different places.
THE PROBLEM: Health data cannot be effectively combined for analysis
A significant barrier to harnessing the full potential of health data is that individual organisations adopt vastly different data standards to collect and store data. This has led to unstructured health datasets, creating huge reproducibility crises and impeding data interoperability.
THE SOLUTION: Health data standardisation
Essential health data often takes the form of large, unstructured datasets, but health data standardisation enables this data to be brought together and be interoperable.
Common Data Models (CDMs) are being utilised more widely in the healthcare sector to overcome the lack of consistency in health data

Health data standardisation refers to bringing data into an agreed-upon common format that allows for collaborative analysis.
The role of common data models in enabling data standardisation
Adopting CDMs, a standard collection of extensible schemas that provides common terminologies and formats, enables researchers to overcome the challenges of unstructured clinical datasets.
Collaborative health research on data across nations, sources, and systems is made possible by the standard approach to health data transformation provided by CDMs. Combining, accessing and analysing information is simpler when all health data are organised following a single worldwide standard.
Stakeholder-driven initiatives are progressing in implementing frameworks and building networks to support this mission. Examples of CDMs for clinical data are the:
What is OMOP?
OMOP is an open community data standard created to standardise observational data formats and content and to facilitate quick analyses. The OHDSI standardised vocabulary is a key part of the OMOP CDM. The OHDSI vocabularies enable standard analytics and allow the organisation and standardisation of medical terms to be used across the various clinical domains of the OMOP CDM.
What is CDISC?
OMOP is an open community data standard created to standardise observational data formats and content and to facilitate quick analyses. The OHDSI standardised vocabulary is a key part of the OMOP CDM. The OHDSI vocabularies enable standard analytics and allow the organisation and standardisation of medical terms to be used across the various clinical domains of the OMOP CDM.
What is FHIR?
OMOP is an open community data standard created to standardise observational data formats and content and to facilitate quick analyses. The OHDSI standardised vocabulary is a key part of the OMOP CDM. The OHDSI vocabularies enable standard analytics and allow the organisation and standardisation of medical terms to be used across the various clinical domains of the OMOP CDM.
Why is health data standardisation important?
It is increasingly important that health data undergo standardisation for various reasons.
The world's health data assets are currently not being utilised to their full potential
There are several reasons for this including:
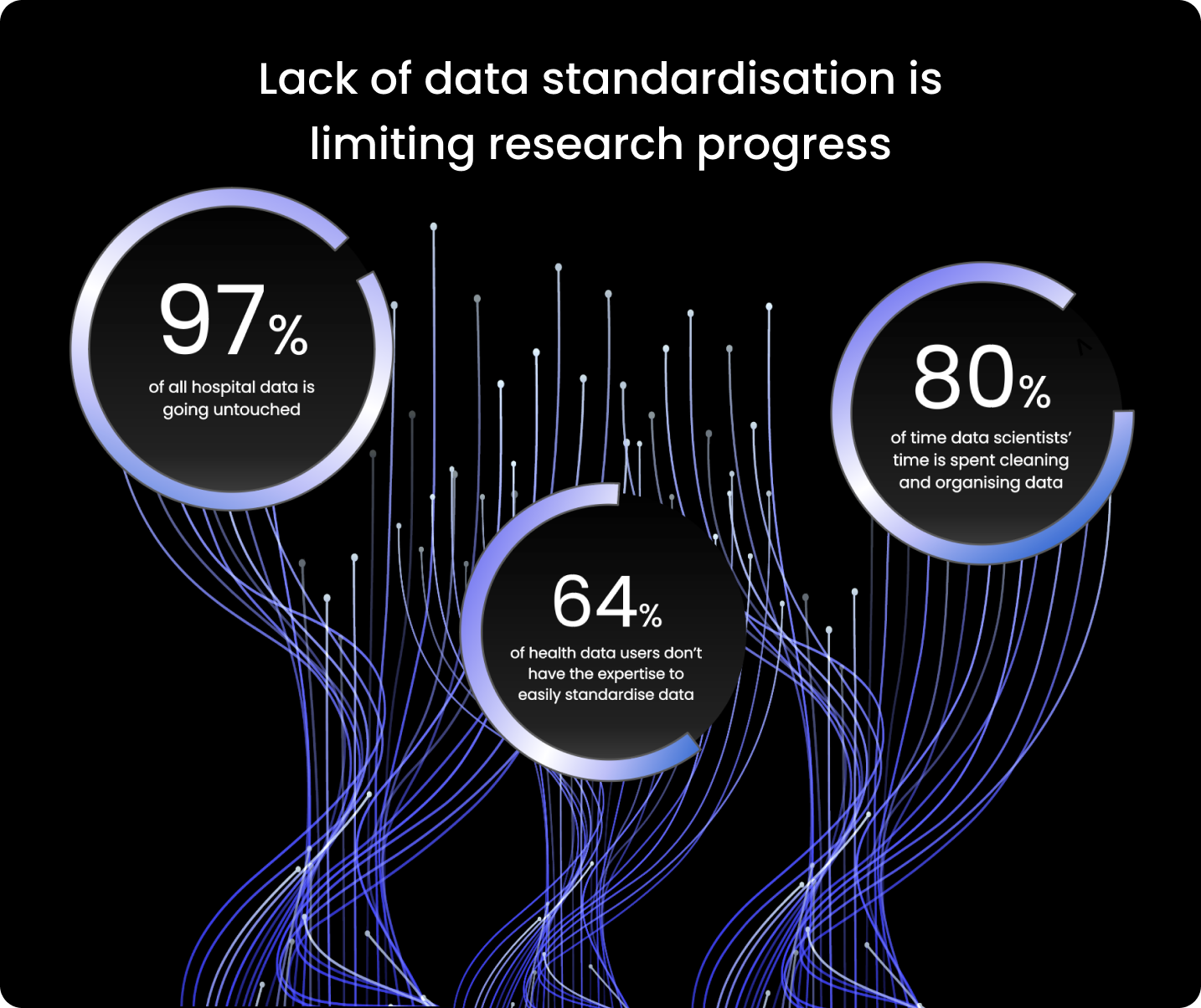
The World Economic Forum estimates that
97% of hospital data goes unused.
Since the majority of users of health data (64%) lack the knowledge necessary to standardise data quickly, researchers spend too much time preparing the data for analysis.
According to some estimates, data scientists devote 80% of their work to organising and cleaning data. It is clear that limited health data standardisation stalls research progress.
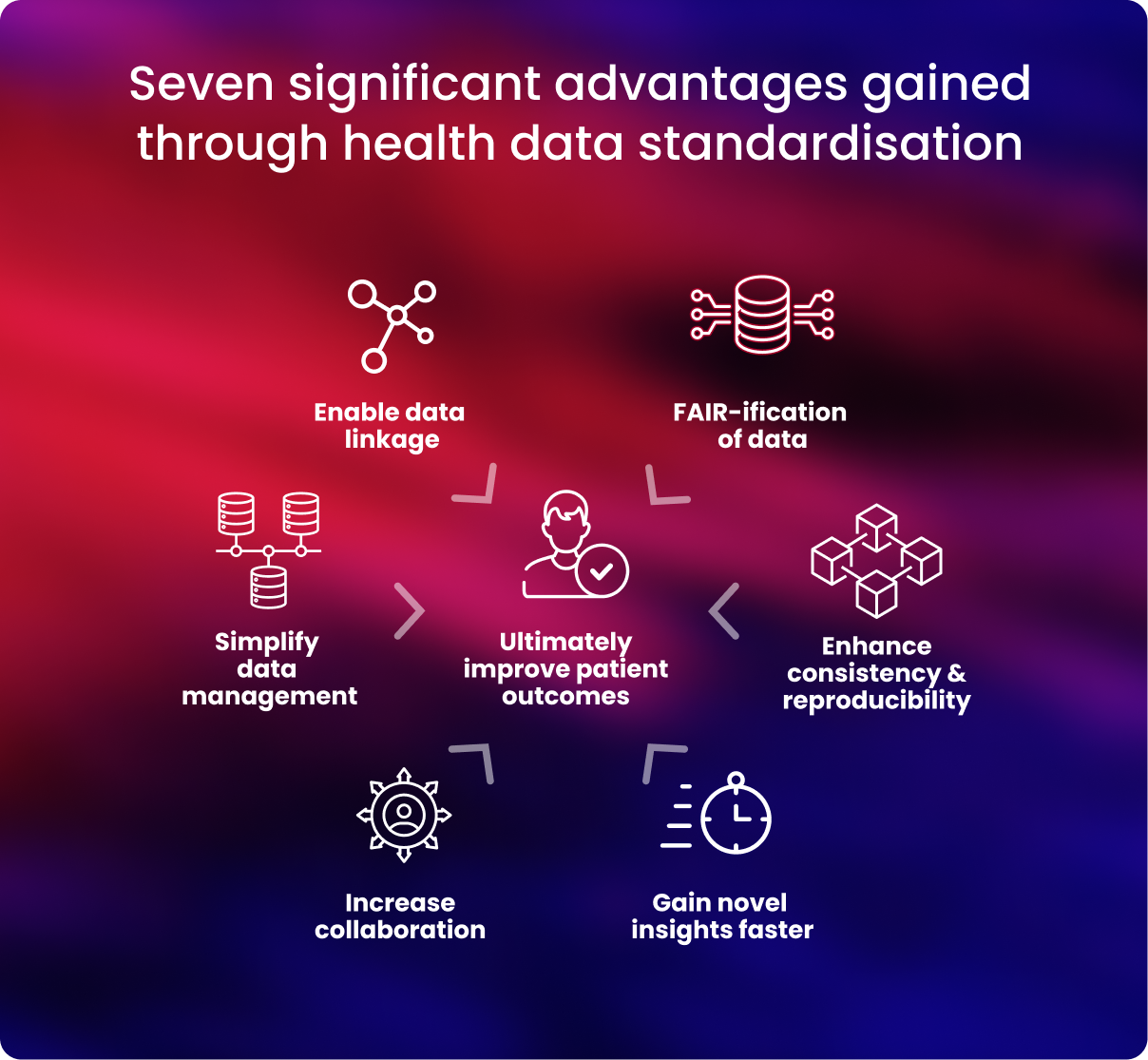
What are the benefits of standardising the health data?
Health data must be standardised and harmonised before researchers can collaborate quickly and effectively across global health data resources. Increased collaboration can lead to new insights and discoveries in the healthcare and research sector.
Below are further details on some key benefits gained when health data is standardised.
Enabling health data standardisation - technical challenges and solutions
While it is clear that many benefits can be gained by standardising health data to a common format, it is not without technical challenges. Below are some challenges researchers can face when standardising health data.

Key players driving health data standardisation
International initiatives are coming together to tackle the issue of limited health data collaboration and interoperability. Some of these are listed below:

Global Alliance for Genomics and Health (GA4GH)
A worldwide policy-framing alliance across 90 countries of various stakeholders, recognises the urgent need to enable broad data sharing across the borders of any single institution or country. Additionally, they highlight that researchers are effectively locking away the potential of data to contribute to research and medical advances by not doing this.

A worldwide policy-framing alliance across 90 countries of various stakeholders, recognises the urgent need to enable broad data sharing across the borders of any single institution or country. Additionally, they highlight that researchers are effectively locking away the potential of data to contribute to research and medical advances by not doing this.
![]()
Health Data Research UK (HDR UK) works to integrate health and care data from throughout the UK to allow advancements that enhance people's lives. They combine, enhance, and use healthcare data as a national institute.
![]()
The UK Health Data Research Alliance was formed to bring together leading healthcare and research organisations as an independent union to create best practices for the ethical use of UK health data for large-scale research.
![]()
The European Health Data and Evidence Network (EHDEN) has established a standardised ecosystem of data sources to reduce the time needed to provide answers in health research.
![]()
CDISC is an international, non-profit charity organisation that brings together a community of specialists from many fields to improve the development of data standards. They aim to make data more easily accessible, interoperable, and reusable for research so it can have a bigger impact on global health.
![]()
HL7 FHIR Foundation, an international, non-profit organisation. The foundation offers data, tools, and project support to aid in the collaboration, alignment, and growth of the FHIR community. To enhance healthcare quality, efficacy, and efficiency, the foundation works to make health data more interoperable.
Health data standardisation in action: enabling data linkage
Health data transformation has clear advantages, but what has it helped clinicians and researchers achieve so far?
Bigger, better, more complex datasets may be produced when several forms of health information on the same individual are standardised and then linked, such as when electronic primary care records are integrated with hospital mortality statistics.

Data linkage can involve bringing together multiple relevant datasets for the same individual. These datasets may have been collected in different formats but must all be standardised. Data linkage can offer a more complete picture of a person's health, allow for better clinical trial follow-up, and collect real-world data on whole populations to help shape health policy. This presents more opportunities for researchers to make novel discoveries and advance healthcare.
Data linkage, however, has its challenges. Patient trust and consent, as well as ensuring that data management and usage are properly regulated, standardised and of appropriate quality, are all potential areas that must be considered.
What has data linkage enabled researchers to discover?
Standardised, linked datasets can provide important insights and eventually enhance lives. As shown in the image above, these linked datasets help form a complete picture of a person’s health.
Recent groundbreaking studies that illustrate the power of big, standardised data in health research include
- research confirming that high blood pressure is a risk factor for dementia- here, the National Institutes of Health (NIHs) All of Us database of EHRs on +125,000 participants was utilised
- the 100,000 Genomes study on rare diseases.
- research reporting the host characteristics triggering severe COVID-19 on approximately 60,000 participants.
Featured resource: Read our blog on data linkage- Better together: the promise of health data linkage - and its challenges
Future outlook: What can be discovered when more health data is standardised and linked?
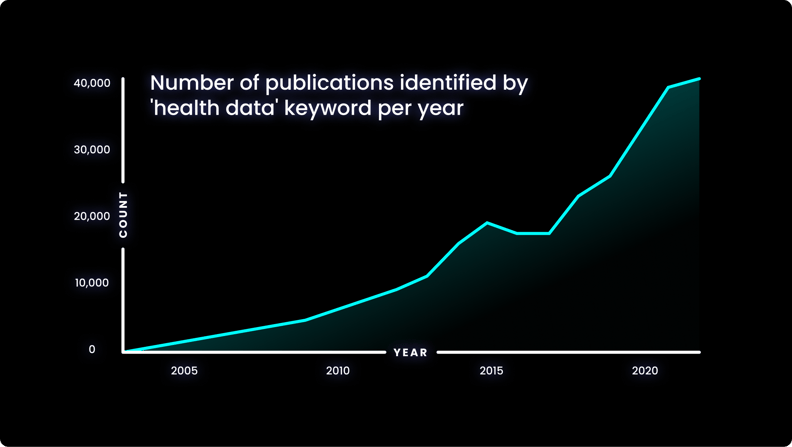
The increasing prevalence of health data in research is evident when considering the quantity of search results on PubMed for the terms ‘health data’- shown in the graph below.
The number of results for this term has increased significantly in recent years, and this is a trend that shows no sign of slowing down.
Globally, initiatives are investing in the continued collection, standardisation and analysis of linked health data to improve patient outcomes:
- In the UK, Our Future Health has begun linking multiple health sources and health-relevant information for up to five million participants. This will help create an incredibly detailed picture that reflects the whole of the UK population
From this, researchers will be able to make discoveries about both health and disease states, such as:
- generating individual risk scores for diseases – enabling precision medicine, better testing of emerging diagnostics and treatments.
- closing the gap in health inequality by including data more reflective of the diverse population of the UK.
- In the US, one million Americans are being asked to participate in the NIH’s All of Us Research Programme to create one of history’s most varied health datasets.
Researchers will use the information to understand better how biology, way of life, and environment impact health. They could use this to discover cures and illness prevention measures.
By enabling comprehensive, standardised data analysis, eradicating fragmented access to data and opening up secure access to distributed biomedical data, precision medicine approaches to health and disease can truly be realised.
In Brazil, Gen-t aims to combine biotechnology with genomic data from the country's population. Currently, 78% of all genomic data available for research comes from people with white European ancestry, while less than 1% t is from people of Latin American / Hispanic origin.
This imbalance significantly limits scientific insights’ impact on those in the region. To address the problem, Gen-T aims to involve 200,000 participants across five years and believes that increasing the variety of global genomic data will speed medical advances.
Health data standardisation: one part of the end-to-end data analysis pipeline
A key advantage of data transformation is that once data has been harmonised, users can bring industry-standard analysis tools to the secure environment where the data is stored.
However, to enhance the insights that may be acquired, the secure access to and analysis of the data should ideally be coordinated into a single solution. A comprehensive method of accessing, connecting, and analysing data while maintaining security is necessary to support data-driven research and innovation.
The advent of automated health data standardisation, trusted research environments and federated data analysis can provide the long-needed, comprehensive solution to balancing efficient data standardisation, access, analysis and security.
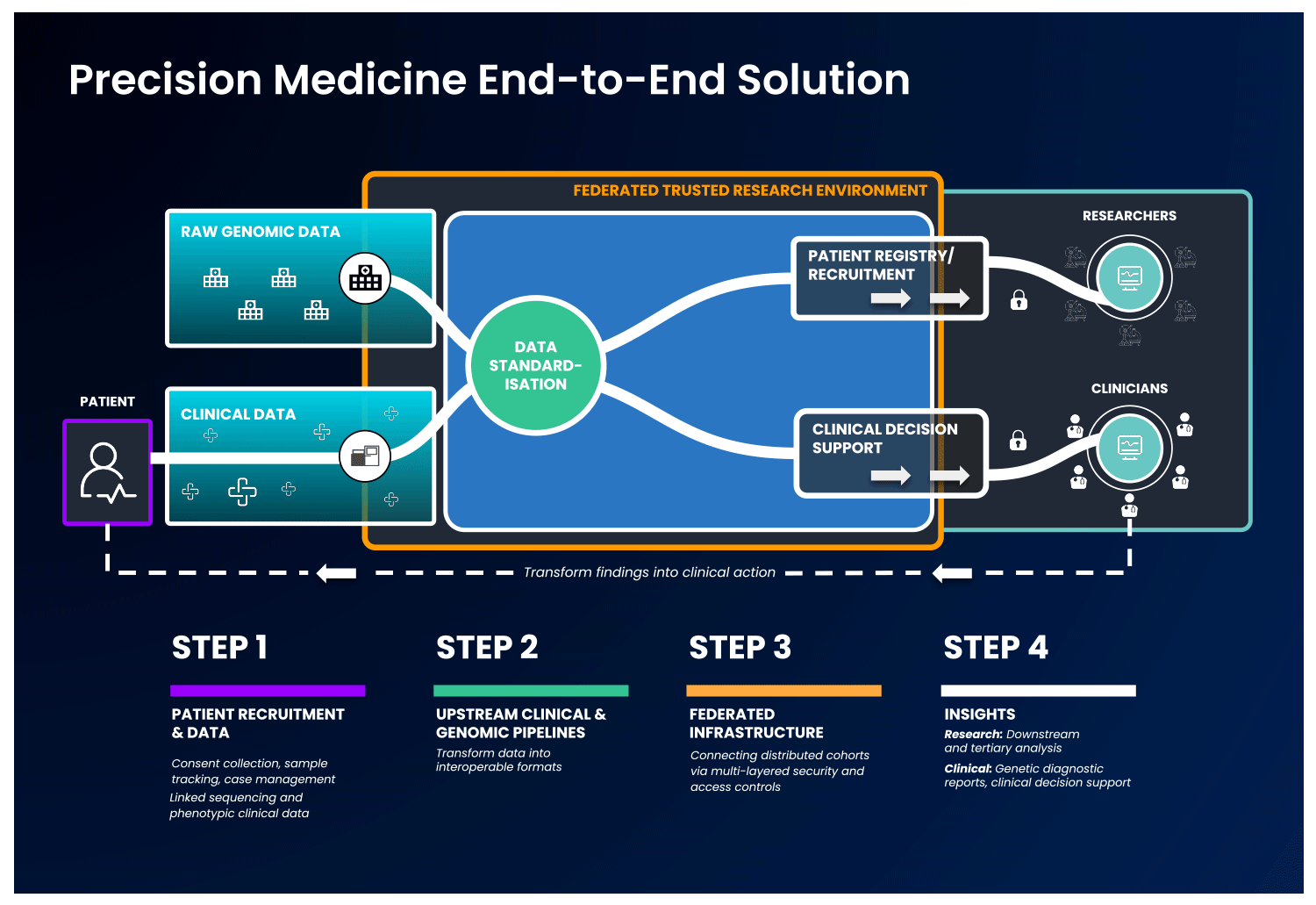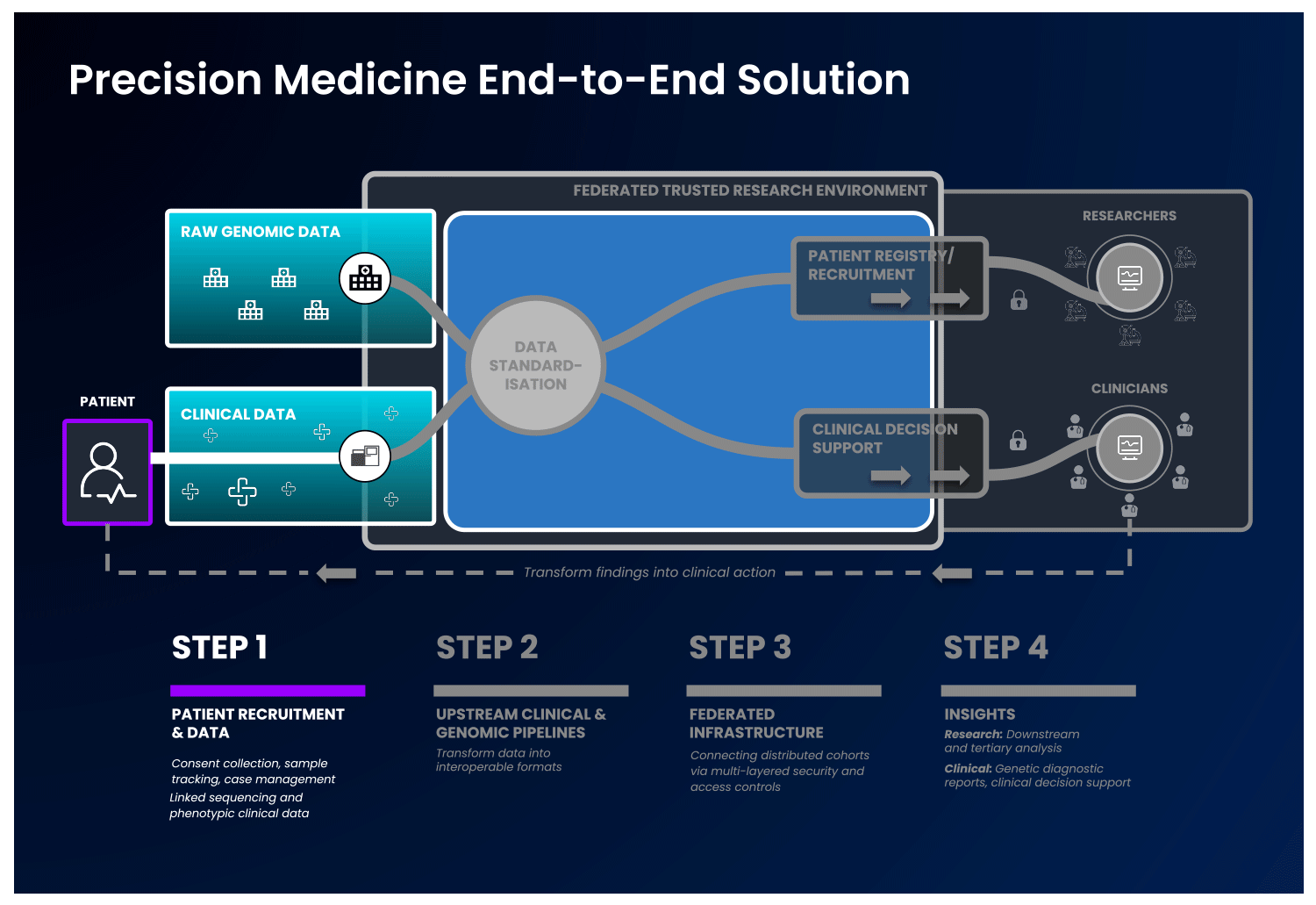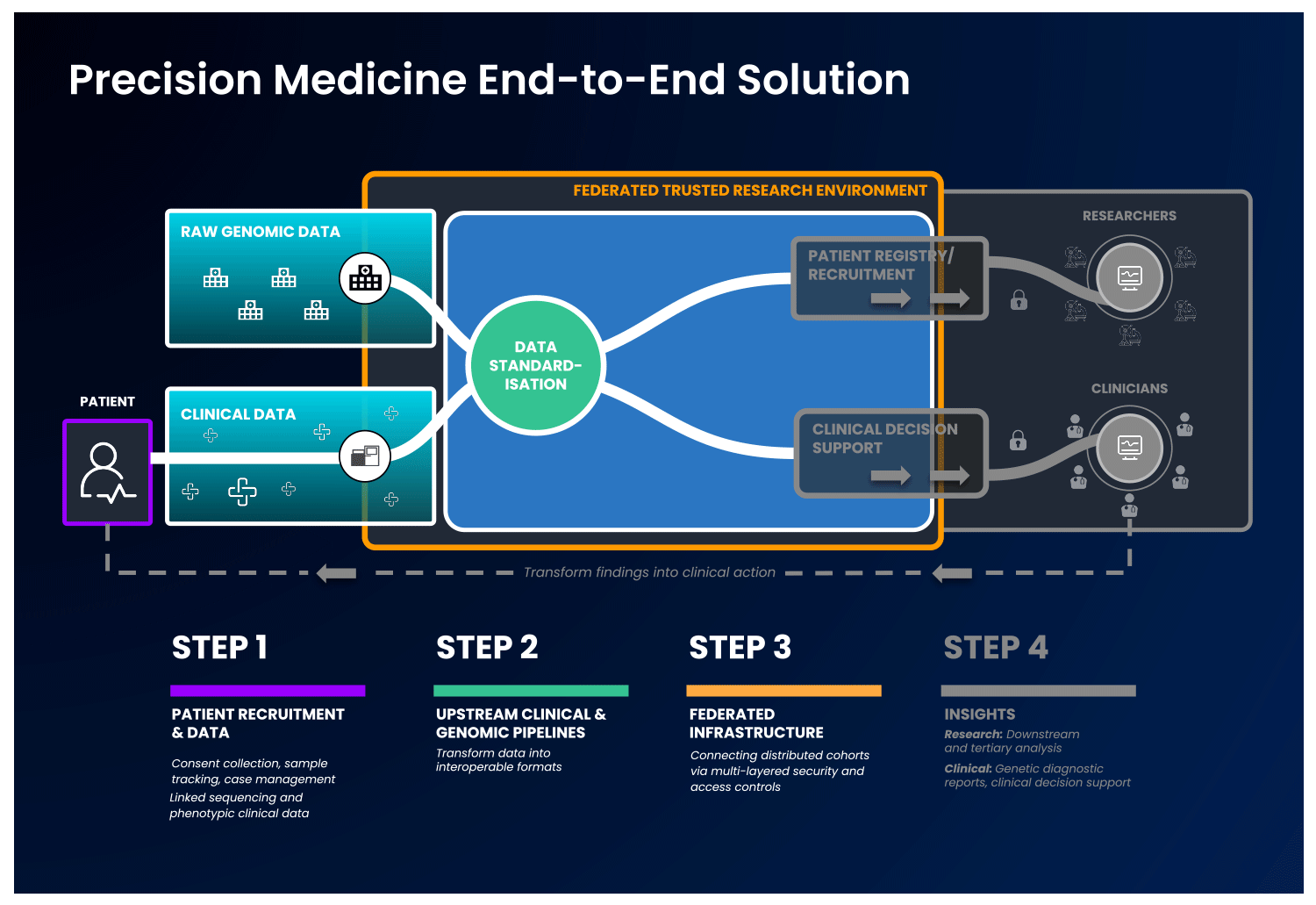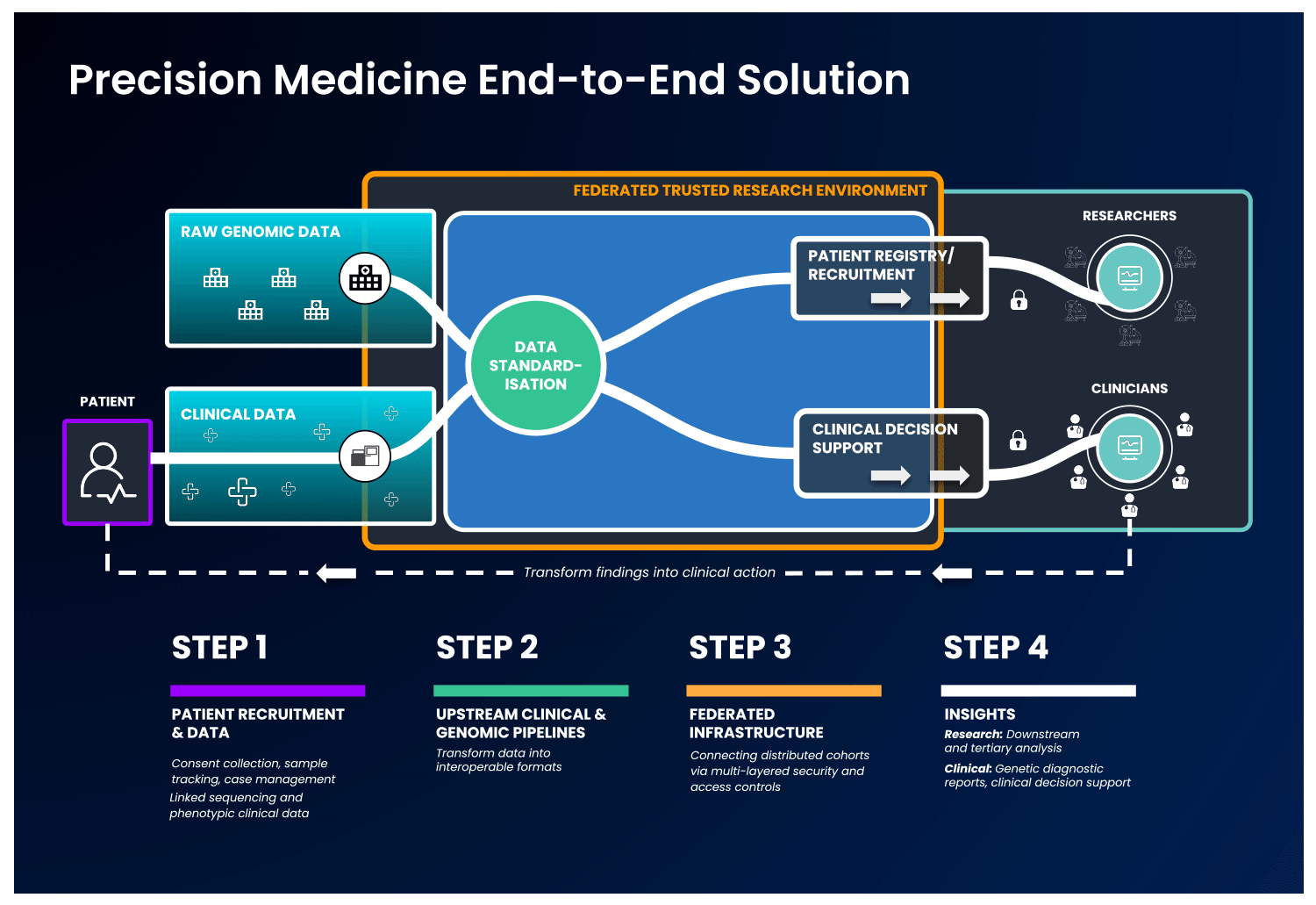
In an end-to-end, single solution, health data is first collected and standardised into interoperable formats. Next, these data are ingested into a cloud-based federated architecture, as described previously, to allow authorised users to access and combine this data with other disparate sources. With this, users can select unique and valuable cohorts of interest and perform downstream analysis without ever having to move the data, to benefit patients without compromising data security.
Strict security measures should govern the end-to-end solution. Security safeguards should be present at the levels of access, data and system security, with specific measures detailed in the image below:
It is possible to imagine an end-to-end platform that could securely integrate a country’s healthcare network, national genomic medicine initiatives and sequencing laboratories, progressing therapeutic discovery while keeping the data safe.
By taking full advantage of advances in data standardisation, cloud computing, federated data analysis and end-to-end data management platforms, research institutions, healthcare systems, and genomic medicine programs globally can harness the benefits of collaboration and joint analyses.
Finally, connecting diverse datasets can also help democratise access to data and insights while ensuring organisations retain autonomy over data.
Featured resource: Catch up on our data diversity webinar where we were joined by Prof Lygia V. Pereira, CEO and Co-Founder, gen-t Science, Victor Angel-Mosti, CEO and Founder of Omica.bio to discuss the challenges and opportunities surrounding health equity.
End-to-end, low-code platforms are democratising access and providing new perspectives on clinical-genomic data, advancing research and leading to significant therapeutic discoveries. These efforts will facilitate benefits sharing and promote equitable access to data and clinical insights and international scientific collaboration.
Summary
Health information exists in a wide variety of formats and sources. Data can only be properly integrated to provide fresh insights when standardised and interoperable.
Standardising health datasets is crucial to guarantee data quality and promote collaboration in healthcare and research. This process, combined with end-to-end data access and analysis solutions, is crucial to standardise, store and integrate healthcare data to deliver actionable insights.
Author: Hannah Gaimster, PhD
Contributors: Hadley E. Sheppard, PhD and Amanda White
About Lifebit
Lifebit provides health data standardisation, TREs and federated data analysis for clients, including Genomics England, Boehringer Ingelheim, Flatiron Health and more, to help researchers transform data into discoveries.
Lifebit’s services are making health data usable quickly.
Interested in learning more about Lifebit’s health data standardisation services and how we accelerate research insights for academia, healthcare and pharmaceutical companies worldwide?
References
- Papez, V. et al. Transforming and evaluating the UK Biobank to the OMOP Common Data Model for COVID-19 research and beyond. J. Am. Med. Inform. Assoc. 30, 103–111 (2023).
- Hume, S., Aerts, J., Sarnikar, S. & Huser, V. Current applications and future directions for the CDISC Operational Data Model standard: A methodological review. J. Biomed. Inform. 60, 352–362 (2016).
- Vorisek, C. N. et al. Fast Healthcare Interoperability Resources (FHIR) for Interoperability in Health Research: Systematic Review. JMIR Med Inf. 10, e35724 (2022).
- Junkai Lai et al. Existing barriers and recommendations of real-world data standardisation for clinical research in China: a qualitative study. BMJ Open 12, e059029 (2022).
- Wilkinson, M. D. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 3, 160018 (2016).
- Vesteghem, C. et al. Implementing the FAIR Data Principles in precision oncology: review of supporting initiatives. Brief. Bioinform. 21, 936–945 (2020).
- Mayo, K. R. et al. The All of Us Data and Research Center: Creating a Secure, Scalable, and Sustainable Ecosystem for Biomedical Research. Annu. Rev. Biomed. Data Sci. 6, 443–464 (2023).
- Alvarellos, M. et al. Democratizing clinical-genomic data: How federated platforms can promote benefits sharing in genomics. Front. Genet. 13, (2023).
- Visscher, P. M. et al. 10 Years of GWAS Discovery: Biology, Function, and Translation. Am. J. Hum. Genet. 101, 5–22 (2017).
- Grannis, S. J. et al. Evaluating the effect of data standardization and validation on patient matching accuracy. J. Am. Med. Inform. Assoc. 26, 447–456 (2019).
- Schneeweiss, S., Brown, J. S., Bate, A., Trifirò, G. & Bartels, D. B. Choosing Among Common Data Models for Real-World Data Analyses Fit for Making Decisions About the Effectiveness of Medical Products. Clin. Pharmacol. Ther. 107, 827–833 (2020).
- The Galaxy Community. The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2022 update. Nucleic Acids Res. 50, W345–W351 (2022).
- Ehsani-Moghaddam, B., Martin, K. & Queenan, J. A. Data quality in healthcare: A report of practical experience with the Canadian Primary Care Sentinel Surveillance Network data. Health Inf. Manag. J. 50, 88–92 (2021).
- Rehm, H. L. et al. GA4GH: International policies and standards for data sharing across genomic research and healthcare. Cell Genomics 1, 100029 (2021).
- Nagar, S. D. et al. Investigation of hypertension and type 2 diabetes as risk factors for dementia in the All of Us cohort. Sci. Rep. 12, 19797 (2022).
- 100,000 Genomes Pilot on Rare-Disease Diagnosis in Health Care — Preliminary Report. N. Engl. J. Med. 385, 1868–1880 (2021).
- Kousathanas, A. et al. Whole-genome sequencing reveals host factors underlying critical COVID-19. Nature 607, 97–103 (2022).
- Sirugo, G., Williams, S. M. & Tishkoff, S. A. The Missing Diversity in Human Genetic Studies. Cell 177, 26–31 (2019).