%20(1).png)
%20(1).png)

In this article:
The term federation comes from the word foederis in Latin, which translates as a treaty, agreement, or contract. When the term federated is used, it usually refers to linking autonomously operating objects. 1
The word federated may be more familiar when it’s used in the context of governments. For example, states can be federated to form a single country, or multiple companies can function together as a federation. The advantages that can be gained when states or objects join together are clear, they can be more powerful and have more impact by combining forces in this way, rather than working alone, in isolation.
Defining federated data analysis
Data federation is solving the problem of data access, without compromising data security. In its simplest terms: Data federation is a software process that enables numerous databases to work together as one. Using this technology is highly relevant for accessing sensitive biomedical health data, as the data remains within appropriate jurisdictional boundaries, while metadata is centralised and searchable and researchers can be virtually linked to where it resides for analysis.
This is an alternative to a model in which data is moved or duplicated then centrally housed - when data is moved it becomes vulnerable to interception and movement of large datasets is often very costly for researchers.
- Federated architectures of individual organisations may be connected together into a federated data platform, enabling data access for users across organisations.
- Federated data analysis takes access a step further and brings approved researcher’s analysis and computation to where the data resides. Federated data analysis allows researchers to analyse data across multiple distinct organisations in a secure manner.
Is federated data analysis the same as federated learning?
These terms refer to quite distinct ideas. Federated learning is when researchers train machine learning (ML) algorithms/models across dispersed data/platforms whilst the data remains in place.2
Federated data analysis however is when researchers perform joint querying and analyses on data across distributed locations or platforms. So, whilst they share the same concept of enabling research analyses to be done without centralising data collection, they have different purposes and outcomes.
The diagram below shows how federated data analysis works. More traditional methods of data access would typically involve researchers accessing data by downloading the data from where it is stored separately to an institutional computing cluster (steps 1 and 2). However in federated data analysis, the analysis is securely brought to where the distributed data lies (step 3).
.gif?width=1920&height=1080&name=Federation_GIF_Frames_animation_withtext%20(1).gif)
What are the different levels of federation?
There is no single approach to federation and various configurations will entail different legal, compliance, and technical requirements (Table 1). Full federation refers to when both data and compute access are federated over distributed compute and databases to allow querying and joint analyses on the data. However, there also exists a potential for partial federation (I and II) when either compute access or data access are federated and compute or databases are distributed.
When is federated data analysis useful?
Today, huge datasets are the norm in research and healthcare. There are many reasons for this, including the digitisation of many healthcare tools and massively reduced costs for high throughput technologies like sequencing.3
This has lead to a large increase in the amount and quantity of many types of healthcare and biomedical data including:
CLINICAL TRIAL DATA:
Clinical trials are performed to assess the effects of one treatment compared to another, and to see if a new drug offers any improvements. The number of clinical trials, and therefore the amount of data being generated during clinical trials, being conducted worldwide is constantly increasing. There was a fivefold increase in the number of trials between 2004-2013 for example.4
REAL WORLD DATA (RWD):
Per the definition by the US Food and Drug Administration, real-world data (RWD) in the medical and healthcare field “are the data relating to patient health status and/or the delivery of healthcare routinely collected from a variety of sources. The amount of RWD is increasing, which is not surprising when considering where this data comes from; places such as electronic health records (EHR), social media accounts and many other tech-driven sources and wearable devices. 5
NEXT GENERATION SEQUENCING (NGS):
This type of work produces billions of short reads per experiment. 6 Furthermore, it is estimated that over 60 million patients will have had their genome sequenced in a healthcare context by 2025. 7
ADDITIONAL 'OMICS' TECHNOLOGIES:
These include proteomic, transcriptomic, metabolomic approaches and the amount of data produced by these studies is increasing every year. 8 An example where researchers have taken multiple omics approaches is The Cancer Genome Atlas Programme which contains 2.5 petabytes of omics data.These large datasets are often coupled with artificial intelligence (AI) and advanced analytics approaches. These complex additional analyses and combinations of data further contribute to the huge increase in the quantity of health data. Furthermore, these are sensitive datasets, which may contain identifiable patient data or data that may be commercially sensitive, so there are valid security and privacy concerns surrounding safe access.Taken together this produces a tough problem in enabling researchers to securely access, analyse and draw novel insights from them.
The World Economic Forum estimates that
97% of hospital data goes unused.
The challenge: datasets are siloed so insights are limited
Most of this potentially life-saving data is distributed across the globe and stored in siloed, inaccessible locations that keep data secure but prevent its use. In a stark example, the World Economic Forum states that 97% of all hospital data goes unused.
Further, there is a growing number of regulations and policies to protect sensitive data, such as GDPR in Europe and the Health Insurance Portability and Accountability Act (HIPAA) Safe Harbour rule in the US.
Today, researchers are stifled by restrictions on data access. Agreements to enable data sharing between organisations are slow, typically taking organisations six months or more to gain data access. 9 Further, this data access is often provided via inflexible platforms with limited functionality.
Data access and usability has become a significant barrier in research progress and therapeutic discovery. Researchers should be enabled to access and use this health data to make new discoveries and improve patient outcomes. An effective way to achieve secure data interoperability and access across the distributed healthcare ecosystem is through federated data analysis.
The solution: federation enables secure access to data
Federated data analysis promotes secure, international collaboration, bridging access across different countries and jurisdictional regulations. It also increases data analysis power whilst retaining control over cost - as no expensive data copying or egress is required. In the healthcare setting, federation is increasingly important in securely providing access to sensitive data such as real world or genomic data.
In this video Professor Serena Nik-Zainal, Professor of Genomic Medicine and Bioinformatics at The University of Cambridge, explains why researchers need to securely access health data and how organisations are solving this problem using federated data analysis.
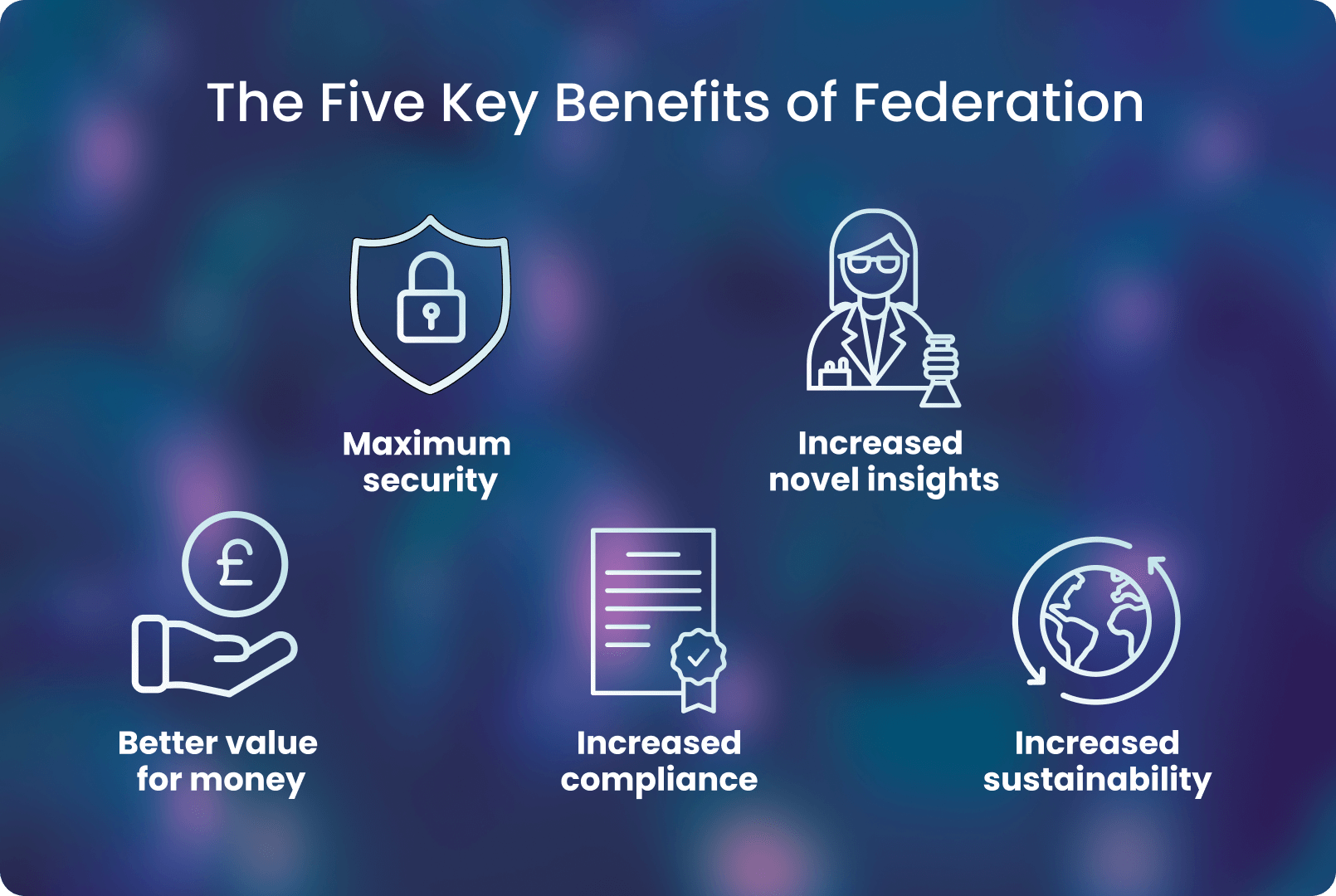
What are the advantages of federation for health and genomic data?
There are many advantages in using federated analysis for health and genomic data, which are summarised below
Federated analysis for health and genomic data provides multiple benefits:
Federated data analysis in action: using data to tackle the Covid-19 pandemic
Worldwide, large population genomics sequencing projects are being established with the aim of implementing population-level genomic medicine. Genomics is the study of the complete set of DNA in a person or other organism. With DNA underpinning a large proportion of an individual's health and disease status, a genomic medicine approach is increasingly being applied in clinical settings.
Here, the study of clinical outcomes (measurable changes in health and well-being) is combined with genomics so researchers can better understand how a person’s genome contributes to disease. Increasingly, advances in our understanding of the genome are contributing to improvements in disease diagnosis, drug discovery and targeted therapeutics.13 14
In the UK, the genomic medicine efforts have been spearheaded by Genomics England and its 100,000 Genomes Project, one of the largest cohorts of rare disease, infection and cancer patients globally.
During the pandemic, Genomics England worked with the NHS to deliver whole genome sequencing of up to 20,000 COVID-19 intensive care patients, and up to 15,000 people with mild symptoms. This allowed researchers to query, analyse and collaborate over these very large sets of genomic and medical data in seconds. Its enhanced functionality and automated tools helped researchers’ understanding of the underlying genetic factors that may explain what makes some patients more susceptible to the virus, or more severely ill when infected.15
Featured resource:
Watch how this secure data access was enabled in this video from Lifebit’s Chief Business Development Officer Thorben Seeger and Population Genomics Lead Filippo Abbondanza.
The ability to obtain secure data access going forward, whilst meeting the needs of researchers, organisations and governments, will support research at scale so the maximum scientific insights can be gained, in the quickest time frame.
What else has health data federation helped us achieve so far?
It’s not too surprising that federation is gaining popularity amongst big data initiatives across the life sciences sector and having impressive impacts. Examples across industries worldwide include:
POLICY / GOVERNMENTS:
A recent Genome UK policy paper produced by the UK government outlined their plan to set up a federated infrastructure for the management of UK genomics data resources. The paper states that adopting a federated approach to genome data access will enable wide-reaching benefits for patients, the NHS and will ensure that a patient’s genomic data can inform their care throughout their life.
STANDARDS SETTING ORGANISATIONS:
The Global Alliance for Genomics and Health (GA4GH), which was set up to promote the international sharing of genomic and health-related data, endorses a federated analysis approach.7 GA4GH states that federation offers organisations more control without limiting collaboration and openness, whilst remaining flexible and adaptable to specific contexts.
INTERNATIONAL BIOBANKS:
- Canadian Distributed Infrastructure for Genomics (CanDIG) employs federation to draw insights from both genomic and clinical datasets. 16 In Canada each province has its own health data privacy legislation so data generated in each province must follow provincial governance laws. The CanDIG platform tackles this using a fully distributed federated data model, enabling federated querying and analysis while ensuring that local data governance laws are complied with.
- Australian Genomics, the national genomics service in Australia is also developing a federated repository of genomic and phenotypic data to bridge the gap between its national health system and state-funded genetic services.17
- Recently, multi-party federation was successfully demonstrated between trusted research environments (TREs) for the first time in the UK, linking the TREs of the University of Cambridge and Genomics England - this approach has the potential to remove the geographical, logistical, and financial barriers associated with moving exceptionally large datasets. It will heavily reduce the current time burden on researchers to conduct their analysis over integrated cohorts.
PHARMACEUTICAL COMPANIES
Boehringer Ingelheim recently announced the use of federated data analysis to accelerate research and development work. This will provide powerful analytic capabilities and global biobank connections to build a secure “dataland” for analytics and research, ultimately to help accelerate the development of innovative medicines and improve patient outcomes.
%20(1).png?width=1076&height=807&name=FederationMap%20(1)%20(1).png)
Deploying federated data analysis: standards and infrastructure required
It is clear that federation is the future for enabling secure genomic and health data access, but what is required to start employing this approach as a researcher or organisation?
.png?width=1610&height=702&name=Four%20key%20requirements%20to%20enabling%20federated%20data%20analysis%20(1).png)
There are four prerequisites to federating biomedical data, which are:
1. SUITABLE INFRASTRUCTURE
Additionally, a robust database infrastructure is required for straightforward data handling and integrated data analyses. A highly scalable platform is required to deal with such large data, these are often cloud-based to offer the required flexibility.
2. ADVANCED API, AUTHENTCIATION AND ANALYSIS TECHNOLOGY
A platform that can interface with distributed data sources and other platforms is needed so that federated linkage can be achieved. This typically requires:
- a set of APIs that enable computational coordination and communication (i.e. federation) between platforms to allow federation
- the ability to merge authentication/authorisation systems for researchers accessing data across platforms.
- the platform should have all the downstream tools needed to run analyses on the federated data.
3. STANDARDISED DATA
Data needs to be standardised to a common data language (CDM) such as Observational Medical Outcomes Partnership (OMOP). When health data are all structured to a common international standard, it makes merging and analysing datasets across distributed sources and platforms possible as they become interoperable.
Featured resource:
Read Lifebit’s white paper on best practices for data standardisation
4. MAXIMUM SECURITY
Finally, as federation of patient or volunteer data will involve highly sensitive health information, it is imperative to ensure all data is secure. This will involve:
- strong data encryption standards. Data should be encrypted at all stages including at rest (eg when data is in storage), in transfer (eg when data is moving between storage buckets and compute machines) and during analysis.
- pseudonymisation of data
- role-based access control to data can only be de-encrypted by authenticated
- staff, and the security network imposes additional constraints on which specific users can access, view, or edit encrypted files.
- consideration of how results will be securely exported, i.e via an Airlock process.
What's next for data federation?
The next section considers the future opportunities and challenges for data federation.
1. DEMOCRATISING ACCESS TO DATA AND INSIGHTS
To advance health data research safely, there must be strict regulations over how data is governed and accessed that are applied at the organisational- and researcher-level. The advantages of increased security and reduced cost that federation brings can help to securely democratise health data access, by enabling more data custodians to securely share, access and collaborate over data. This will help fully democratise access to health data and the insights derived.
.png?width=1076&height=845&name=Federation%20Graphic%20(1).png)
2. IMPROVING REPRESENTATION / DIVERSITY IN GLOBAL HEALTH DATA
The vast majority of genomic studies performed to date represent populations of European ancestry.18
This lack of diversity in genomics research is a real issue as the potential insights that can be gained from such studies (for example, increased understanding of disease prevalence, early detection and diagnosis, rational drug design and improved patient care and outcomes) may not be relevant to the underrepresented populations absent from a sample, leading to misdiagnosis, poor understanding of conditions and inconsistent delivery of care.19
As a result, genomic medicine does not always benefit all people equally. A worldwide, concerted engagement effort and increased transparency is required to help improve public trust and willingness to engage in research for underrepresented communities.
However, it is also possible that federated platforms, with its associated benefits of lower cost, could help make big data analytics more accessible to lower and middle income countries. Additionally, they can help improve diversity of the cohorts that can be built and accessed via federated networks.
3. ENHANCING COLLABORATION ACROSS THE WORLD'S DISTRIBUTED DATA
An additional aim for the future is to enable widespread multi-party federation20 21 that spans international borders and sectors, eg international public-private federation. This will require significant work to develop the policies and governance procedures across countries and companies with different compliance requirements. However, federated data analysis can provide secure data access at scale to researchers, establishing large collaborative data ecosystems to be built. This will allow research to be done across larger and more diverse datasets, improving outcomes.
Summary
In conclusion, data federation can aid researchers, organisations and governments in a variety of ways. It can give researchers secure access to large data sets from around the world, enabling them to run analyses, find answers to pressing research issues, and make scientific discoveries. Federated data analysis maximises financial efficiency by avoiding costly data transfers. Data federation can also help support global collaboration and democratise data access to support fair benefit distribution.
Further reading
Read Lifebit’s white paper on best practices for building a Trusted Research Environment
Read Lifebit’s white paper on security and data governance
Author: Hannah Gaimster, PhD
Contributors: Hadley E. Sheppard, PhD and Amanda White
About Lifebit
At Lifebit, we develop secure federated data analysis solutions for clients including Genomics England, NIHR Cambridge Biomedical Research Centre, Danish National Genome Centre and Boehringer Ingelheim to help researchers turn data into discoveries.
Interested in learning more about Lifebit’s federated data solution?
References
- van der Lans, R. F. Chapter 1 - Introduction to Data Virtualization. in Data Virtualization for Business Intelligence Systems (ed. van der Lans, R. F.) 1–26 (Morgan Kaufmann, 2012). doi:10.1016/B978-0-12-394425-2.00001-0.
- Konečný, J. et al. Federated Learning: Strategies for Improving Communication Efficiency. Preprint at http://arxiv.org/abs/1610.05492 (2017).
- Marx, V. The big challenges of big data. Nature 498, 255–260 (2013).
- Viergever, R. F. & Li, K. Trends in global clinical trial registration: an analysis of numbers of registered clinical trials in different parts of the world from 2004 to 2013. BMJ Open 5, e008932 (2015).
- Liu, F. & Demosthenes, P. Real-world data: a brief review of the methods, applications, challenges and opportunities. BMC Med. Res. Methodol. 22, 287 (2022).
- Yamada, R., Okada, D., Wang, J., Basak, T. & Koyama, S. Interpretation of omics data analyses. J. Hum. Genet. 66, 93–102 (2021).
- Rehm, H. L. et al. GA4GH: International policies and standards for data sharing across genomic research and healthcare. Cell Genomics 1, 100029 (2021).
- Hasin, Y., Seldin, M. & Lusis, A. Multi-omics approaches to disease. Genome Biol. 18, 83 (2017).
- Learned, K. et al. Barriers to accessing public cancer genomic data. Sci. Data 6, 98 (2019).
- Visscher, P. M. et al. 10 Years of GWAS Discovery: Biology, Function, and Translation. Am. J. Hum. Genet. 101, 5–22 (2017).
- Grealey, J. et al. The Carbon Footprint of Bioinformatics. Mol. Biol. Evol. 39, msac034 (2022).
- Lannelongue, L., Grealey, J., Bateman, A. & Inouye, M. Ten simple rules to make your computing more environmentally sustainable. PLOS Comput. Biol. 17, e1009324 (2021).
- Stark, Z. et al. Integrating Genomics into Healthcare: A Global Responsibility. Am. J. Hum. Genet. 104, 13–20 (2019).
- Macken, W. L. et al. Specialist multidisciplinary input maximises rare disease diagnoses from whole genome sequencing. Nat. Commun. 13, 6324 (2022).
- Kousathanas, A. et al. Whole-genome sequencing reveals host factors underlying critical COVID-19. Nature 607, 97–103 (2022).
- Dursi, L. J. et al. CanDIG: Federated network across Canada for multi-omic and health data discovery and analysis. Cell Genomics 1, 100033 (2021).
- Stark, Z. et al. Australian Genomics: A Federated Model for Integrating Genomics into Healthcare. Am. J. Hum. Genet. 105, 7–14 (2019).
- Fatumo, S. et al. Uganda Genome Resource: A rich research database for genomic studies of communicable and non-communicable diseases in Africa. Cell Genomics 2, (2022).
- Fatumo, S. et al. A roadmap to increase diversity in genomic studies. Nat. Med. 28, 243–250 (2022).
- Lunt, C. & Denny, J. C. I can drive in Iceland: Enabling international joint analyses. Cell Genomics 1, 100034 (2021).
- Nik-Zainal S et al. Multi-party trusted research environment federation: Establishing infrastructure for secure analysis across different clinical-genomic datasets. (2022) doi:10.5281/zenodo.7085536.


